
 Contacte
ContacteA qui va dirigit
Aquest how-to va dirigit a tots aquells desenvolupadors/arquitectes que vulguin realitzar un gran volum d’inserts/updates a una aplicació Canigó 3.2.
Versió de Canigó
Els pasos descrits en aquest document apliquen a la versió 3.2.x del Framework Canigó.
Introducció
En aquest HowTo s’explica com realitzar Batch Inserts amb una aplicació Canigó 3.2.
Canigó 3.2 utilitza el framework Spring Data que proporciona un mètode save(Iterable entities) que es pot realitzar per a fer inserts/updates massius, però aquest mètode internament simplement crida al mètode simple save(S entity) amb lo qual no hi ha cap benefici de rendiment entre utilitzar aquest mètode o fer diverses crides al mètode save(S entity)
Per aquesta raó el mòdul de persistència de Canigó 3.2 proporciona el mètode bulkSave(Iterable entities) que optimitza el rendiment quan es realitza un gran volum d’inserts/updates.
Aquest Howto es basa en l’aplicació que genera el plugin de Canigó
EquipamentService
A la classe EquipamentService creem dos mètodes, SaveIterable amb el qual realitzarem una inserció massiva utilitzant el mètode proporcionat per Spring Data, i un altre mètode saveBatch utilitzant el mètode proporcionat pel mòdul de persitència de Canigó 3.2
saveIterable
public void saveIterable (){
List<Equipament> equipaments = new ArrayList<Equipament>();
for (int i = 0; i < 250000; i++){
Equipament e = new Equipament();
e.setMunicipi("Municipi" + System.currentTimeMillis());
e.setNom("Nom" + System.currentTimeMillis());
equipaments.add(e);
if (i % BATCH_SIZE == 0) {
repository.save(equipaments);
equipaments.clear();
}
}
repository.save(equipaments);
}
saveBatch
public void saveBatch (){
List<Equipament> equipaments = new ArrayList<Equipament>();
for (int i = 0; i < 250000; i++){
Equipament e = new Equipament();
e.setMunicipi("Municipi" + System.currentTimeMillis());
e.setNom("Nom" + System.currentTimeMillis());
equipaments.add(e);
if (i % BATCH_SIZE == 0) {
repository.bulkSave(equipaments);
equipaments.clear();
}
}
repository.save(equipaments);
}
Tots dos mètodes el que fan és inserir a BBDD 250.000 registres en blocs de 50.
private static final int BATCH_SIZE = 50;
ResultBatchDTO
Creem un DTO per a mostrar el resultat de tots dos mètodes:
package cat.gencat.plantillarest.model.dto;
import java.io.Serializable;
public class ResultBatchDTO implements Serializable{
private static final long serialVersionUID = 1L;
private Long tempsSaveIterable;
private Long tempsBulkSave;
public ResultBatchDTO() {
}
public Long getTempsSaveIterable() {
return tempsSaveIterable;
}
public void setTempsSaveIterable(Long tempsSaveIterable) {
this.tempsSaveIterable = tempsSaveIterable;
}
public Long getTempsBulkSave() {
return tempsBulkSave;
}
public void setTempsBulkSave(Long tempsBulkSave) {
this.tempsBulkSave = tempsBulkSave;
}
}
EquipamentServiceController
Al nostre endpoint creem un mètode que fa la crida als mètodes que hem creat a la classe EquipamentService:
@RequestMapping(value = "/bulk", method = RequestMethod.POST)
public ResponseEntity<ResultBatchDTO> bulk() {
ResultBatchDTO result = new ResultBatchDTO();
long inici = System.currentTimeMillis();
equipamentService.saveIterable();
long fi = System.currentTimeMillis();
long temps = (fi-inici) / 1000;
result.setTempsSaveIterable(temps);
inici = System.currentTimeMillis();
equipamentService.saveBatch();
fi = System.currentTimeMillis();
temps = (fi-inici) / 1000;
result.setTempsBulkSave(temps);
return new ResponseEntity<ResultBatchDTO>(result, HttpStatus.OK);
}
Aquest mètode el que fa es fer la crida als dos mètodes i ens retorna el temps que ha trigat cada mètode en fer els 250.000 inserts.
Resultat
Despleguem l’aplicació i utilitzant Swagger executem el mètode bulk amb el següent resultat
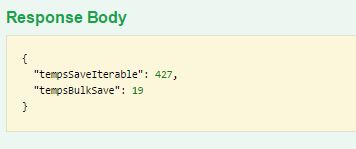
Com es pot veure el temps amb el mètode de Spring Data és de 427 segons, mentres que el mètode optimitzat proporcionat per Canigó 3.2 ha trigat 19 segons