Darrera actualització: 20-05-2022
Components d’Eventhub
Kafka
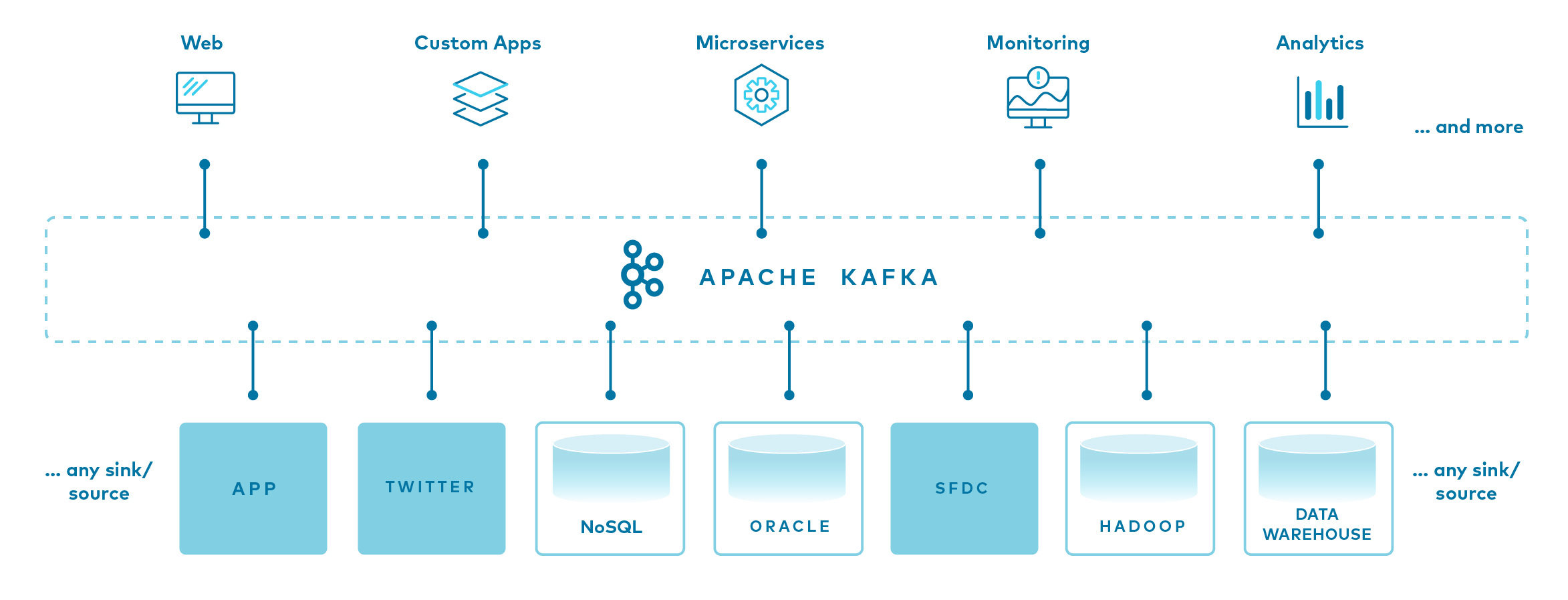 Apache Kafka és una plataforma de transmissió d’esdeveniments distribuïda de codi obert utilitzada per milers d’empreses per a canalitzacions de dades d’alt rendiment, anàlisis de transmissió, integració de dades i aplicacions crítiques.
Apache Kafka és una plataforma de transmissió d’esdeveniments distribuïda de codi obert utilitzada per milers d’empreses per a canalitzacions de dades d’alt rendiment, anàlisis de transmissió, integració de dades i aplicacions crítiques.
Kafka combina tres capacitats clau perquè pugueu implementar els vostres casos d’ús per a la transmissió d’esdeveniments de punta a punta amb una única solució provada en batalla:
- Per publicar (escriure) i subscriure’s a (llegir) fluxos d’esdeveniments, inclosa la importació/exportació contínua de les vostres dades des d’altres sistemes.
- Per emmagatzemar fluxos d’esdeveniments de manera duradora i fiable durant el temps que vulgueu.
- Processar fluxos d’esdeveniments a mesura que es produeixen o de manera retrospectiva.
I tota aquesta funcionalitat es proporciona de manera distribuïda, altament escalable, elàstica, tolerant a errors i segura.
Kafka és un sistema distribuït format per servidors i clients que es comuniquen mitjançant un protocol de xarxa TCP d’alt rendiment.
Servidors: Kafka s’executa com un clúster d’un o més servidors que poden abastar diversos centres de dades o regions del núvol. Alguns d’aquests servidors formen la capa d’emmagatzematge, anomenada brokers. Altres servidors executen Kafka Connect per importar i exportar dades contínuament com a fluxos d’esdeveniments per integrar Kafka amb els vostres sistemes existents, com ara bases de dades relacionals i altres clústers de Kafka. Per permetre’t implementar casos d’ús crítics, un clúster de Kafka és altament escalable i tolerant a errors: si algun dels seus servidors falla, els altres servidors es faran càrrec de la seva feina per garantir operacions contínues sense cap pèrdua de dades.
Clients: us permeten escriure aplicacions distribuïdes i microserveis que llegeixen, escriuen i processen fluxos d’esdeveniments en paral·lel, a escala i de manera tolerant a errors, fins i tot en cas de problemes de xarxa o fallades de la màquina.
Casos dús
Casos d’ús populars d’Apache Kafka.
Missatgeria
Kafka funciona bé com a substitut d’un broker de missatges més tradicional. Els brokers de missatges s’utilitzen per diferents motius (per desacoblar el processament dels productors de dades, per guardar missatges no processats, etc.). En comparació amb la majoria de sistemes de missatgeria, Kafka té un millor rendiment, particions integrades, replicació i tolerància a errors, cosa que el converteix en una bona solució per a aplicacions de processament de missatges a gran escala.
Seguiment de l’activitat del lloc web
El cas d’ús original de Kafka era poder reconstruir un canal de seguiment de l’activitat dels usuaris com un conjunt de fonts de publicació i subscripció en temps real. Això vol dir que l’activitat del lloc (visualitzacions de pàgines, cerques o altres accions que els usuaris poden dur a terme) es publica als topics centrals amb un topic per tipus d’activitat. Aquests feeds estan disponibles per a la subscripció per a una sèrie de casos d’ús, com ara el processament en temps real, la supervisió en temps real i la càrrega a Hadoop o sistemes d’emmagatzematge de dades fora de línia per al processament i la generació d’informes fora de línia.
El seguiment de l’activitat sol tenir un volum molt elevat, ja que es generen molts missatges d’activitat per a cada visualització de la pàgina d’usuari.
Mètriques
Kafka s’utilitza sovint per a dades de seguiment operacional. Això implica agregar estadístiques d’aplicacions distribuïdes per produir fonts centralitzades de dades operatives.
Agregació de logs
Molta gent utilitza Kafka com a reemplaçament d’una solució d’agregació de registres. L’agregació de registres sol recopilar fitxers de registre físics dels servidors i els col·loca en un lloc central (un servidor de fitxers o HDFS potser) per processar-los. Kafka elimina els detalls dels fitxers i ofereix una abstracció més neta de dades de registre o d’esdeveniments com a flux de missatges. Això permet un processament de menor latència i un suport més fàcil per a diverses fonts de dades i el consum de dades distribuïts. En comparació amb els sistemes centrats en el registre com Scribe o Flume, Kafka ofereix un rendiment igual de bon, garanties de durabilitat més fortes a causa de la replicació i una latència d’extrem a extrem molt més baixa.
Stream Processing
Molts usuaris de Kafka processen dades en canalitzacions de processament que consisteixen en diverses etapes, on les dades d’entrada en brut es consumeixen dels topics de Kafka i després s’agreguen, s’enriqueixen o es transformen d’una altra manera en nous topics per a un consum posterior o un processament de seguiment. Per exemple, un canal de processament per recomanar articles de notícies pot rastrejar el contingut d’articles dels canals RSS i publicar-lo en un topic “articles”; un processament posterior podria normalitzar o desduplicar aquest contingut i publicar el contingut de l’article netejat a un topic nou; una etapa final de processament podria intentar recomanar aquest contingut als usuaris. Aquests pipelines de processament creen gràfics de fluxos de dades en temps real basats en els topics individuals. A partir de la 0.10.0.0, una biblioteca de stream processing lleugera però potent anomenada Kafka Streams està disponible a Apache Kafka per dur a terme el processament de dades tal com es descriu anteriorment.
Event Sourcing
Event Sourcing és un estil de disseny d’aplicacions on els canvis d’estat es registren com una seqüència de registres ordenada per temps. El suport de Kafka per a dades de registre emmagatzemades molt grans el converteix en un excel·lent backend per a una aplicació construïda amb aquest estil.
Commit Log
Kafka pot servir com una mena de commit-log extern per a un sistema distribuït. El log ajuda a replicar les dades entre nodes i actua com a mecanisme de resincronització dels nodes fallits per restaurar les seves dades. La funció de compactació de registres de Kafka ajuda a donar suport a aquest ús. En aquest ús, Kafka és similar al projecte Apache BookKeeper.
Schema Registry
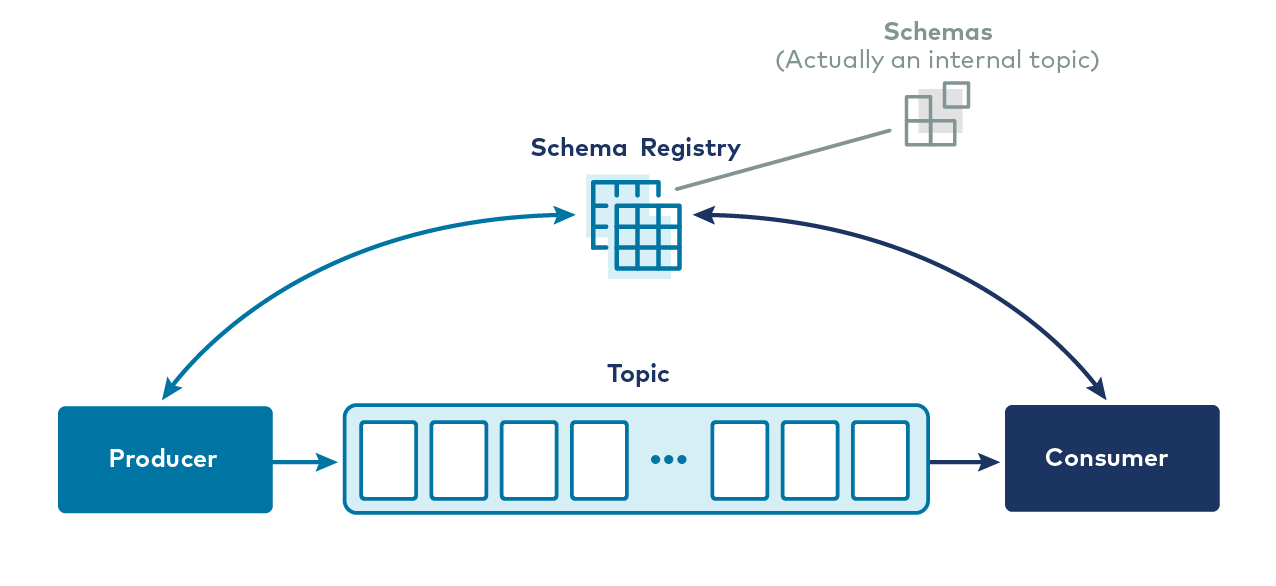 Un cop les aplicacions estiguin ocupades produint missatges a Kafka i consumint-ne missatges, passaran dues coses. En primer lloc, sorgiran nous consumidors de topics existents. Es tracta d’aplicacions noves, potser escrites per l’equip que va escriure el productor original dels missatges, potser per un altre equip, i hauran d’entendre el format dels missatges del topic. En segon lloc, el format d’aquests missatges evolucionarà a mesura que evolucioni el negoci. Els objectes de comanda obtenen un nou camp d’estat, els noms d’usuari es divideixen en nom i cognoms a partir del nom complet, etc. L’esquema dels nostres objectes de domini és un objectiu en constant moviment, i hem de tenir una manera d’acordar l’esquema dels missatges en qualsevol topic determinat.
Un cop les aplicacions estiguin ocupades produint missatges a Kafka i consumint-ne missatges, passaran dues coses. En primer lloc, sorgiran nous consumidors de topics existents. Es tracta d’aplicacions noves, potser escrites per l’equip que va escriure el productor original dels missatges, potser per un altre equip, i hauran d’entendre el format dels missatges del topic. En segon lloc, el format d’aquests missatges evolucionarà a mesura que evolucioni el negoci. Els objectes de comanda obtenen un nou camp d’estat, els noms d’usuari es divideixen en nom i cognoms a partir del nom complet, etc. L’esquema dels nostres objectes de domini és un objectiu en constant moviment, i hem de tenir una manera d’acordar l’esquema dels missatges en qualsevol topic determinat.
Existeix Schema Registry per resoldre aquest problema.
Schema Registry és un procés de servidor autònom que s’executa en una màquina externa als brokers de Kafka. La seva funció és mantenir una base de dades de tots els esquemes que s’han escrit als topics del clúster del qual és responsable. Aquesta “base de dades” es manté en un topic intern de Kafka i es guarda a la memòria cau al registre d’esquemes per a un accés de baixa latència. Schema Registry es pot executar en una configuració redundant i d’alta disponibilitat, de manera que roman activat si falla una instància.
Schema Registry també és una API que permet als productors i consumidors predir si el missatge que estan a punt de produir o consumir és compatible amb les versions anteriors. Quan un productor està configurat per utilitzar Schema Registry, crida a una API al endpoint REST del Schema Registry i presenta l’esquema del missatge nou. Si és el mateix que l’últim missatge produït, el producte pot tenir èxit. Si és diferent de l’últim missatge però coincideix amb les regles de compatibilitat definides per al topic, el producte pot tenir èxit. Però si és diferent d’una manera que infringeix les regles de compatibilitat, el producte fallarà d’una manera que el codi de l’aplicació pugui detectar.
De la mateixa manera, pel que fa al consum, si un consumidor llegeix un missatge que té un esquema incompatible amb la versió que espera el codi del consumidor, Schema Registry li dirà que no consumeixi el missatge. Schema Registry no automatitza completament el problema de l’evolució de l’esquema, això és un repte en qualsevol sistema, independentment de l’eina, però fa que un problema difícil sigui molt més fàcil evitant que es produeixin errors en temps d’execució quan sigui possible.
Kafka Connect
 En el món de l’emmagatzematge i la recuperació d’informació, alguns sistemes no són Kafka. De vegades us agradaria que les dades d’aquests altres sistemes entrin als topics de Kafka i, de vegades, voldríeu que les dades dels topics de Kafka entrin en aquests sistemes. Com a API d’integració d’Apache Kafka, això és exactament el que fa Kafka Connect.
En el món de l’emmagatzematge i la recuperació d’informació, alguns sistemes no són Kafka. De vegades us agradaria que les dades d’aquests altres sistemes entrin als topics de Kafka i, de vegades, voldríeu que les dades dels topics de Kafka entrin en aquests sistemes. Com a API d’integració d’Apache Kafka, això és exactament el que fa Kafka Connect.
D’una banda, Kafka Connect és un ecosistema de connectors endollables, i de l’altra, una aplicació client. Com a aplicació client, Connect és un procés de servidor que s’executa amb maquinari independent dels mateixos brokers de Kafka. És escalable i tolerant a errors, el que significa que podeu executar no només un treballador de Connect, sinó un grup de treballadors de Connect que comparteixen la càrrega de traslladar dades dins i fora de Kafka des i cap a sistemes externs. Kafka Connect també elimina el negoci del codi lluny de l’usuari i, en canvi, només requereix la configuració JSON per executar-se.
Un dels principals avantatges de Kafka Connect és el seu gran ecosistema de connectors. Escriure el codi que mou dades a un magatzem de blobs al núvol, o escriu a Elasticsearch o inseriu registres en una base de dades relacional és un codi que és poc probable que variï d’una empresa a una altra. De la mateixa manera, llegir des d’una base de dades relacional, Salesforce o un sistema de fitxers HDFS heretat és la mateixa operació, independentment del tipus d’aplicació que ho faci. Definitivament, podeu escriure aquest codi, però dedicar el vostre temps a això no afegeix cap tipus de valor únic als vostres clients ni fa que el vostre negoci sigui més competitiu.
Per a més informació podeu contactar amb l’Oficina Tècnica mitjançant e-mail. També podeu consultar l’apartat de Suport.