Darrera actualització: 30-06-2023
Introducció
Definició de ChatGPT
ChatGPT és un sistema avançat de processament de llenguatge natural basat en models de llenguatge neurals (PLN). És capaç de generar respostes coherents i contextualment rellevants en converses textuals, imitant de manera efectiva el comportament humà en un context de xat. Utilitza tècniques d’aprenentatge profund i mecanismes d’atenció per capturar les relacions semàntiques i generar respostes de manera precisa i comprensible.
ChatGPT té una gran versatilitat i pot adaptar-se a diferents sectors i tasques específiques mitjançant l’entrenament i l’ajustament fins i tot als requeriments particulars d’un usuari o aplicació. És una eina potent per millorar les interaccions amb els usuaris, automatitzar tasques de processament de llenguatge i millorar l’experiència de l’usuari en una àmplia gamma d’aplicacions.
Importància del ChatGPT en la indústria del processament del llenguatge natural
Algunes de les raons per les quals ChatGPT és important per aquesta indústria son:
- Avanç en la generació de llenguatge natural: És generen respostes que semblen ser generades per una persona, fet que millora substancialment la capacitat de les màquines per comunicar-se de manera natural amb els humans.
- Millora de les aplicacions de xat: Té un impacte directe en les aplicacions de xat ja que pot ser utilitzat per desenvolupar assistents virtuals, sistemes de suport al client i altres aplicacions interactives. Aquestes aplicacions milloren l’atenció al client, agilitzen la comunicació i permeten respostes ràpides i precises.
- Augment de l’eficiència en tasques de llenguatge: És una eina valuosa per automatitzar tasques de processament de llenguatge. Com per exemple la traducció automàtica, la generació de resums, l’extracció d’informació i altres tasques relacionades amb el llenguatge permetent millorar l’eficiència i la productivitat en diverses indústries.
- Adaptabilitat a diferents sectors : És flexible i pot ser entrenat i adaptat a diferents sectors: com la salut, el comerç electrònic, l’educació, el dret i altres indústries que requereixen d’una interacció efectiva en llenguatge natural.
- Investigació i desenvolupament continuat: L’existència de ChatGPT ha impulsat la investigació i el desenvolupament en el camp del PLN. Ha fomentat la creació de nous models i tècniques per millorar la generació de llenguatge natural, i ha estimulat la col·laboració entre investigadors i professionals del PLN.
Arquitectura de ChatGPT
Descripció general
ChatGPT utilitza l’arquitectura basada en transformers , coneguda com a GPT (Generative Pre-trained Transformer) . Aquesta arquitectura s’ha demostrat extremadament efectiva en tasques de processament de llenguatge natural. L’arquitectura consta de diverses capes de transformadors apilades, cada una amb subcapes d’atenció i capes de retroalimentació (feed-forward). Aquestes capes es combinen per formar una xarxa neuronal profunda.
L’arquitectura està dissenyada per processar seqüències de text amb un enfocament en la generació de llenguatge coherent i contextualment rellevant. Utilitza mecanismes d’atenció (self-attention) per captar les relacions de dependència a llarg termini entre les paraules d’una seqüència. Això permet a ChatGPT processar i comprendre de manera efectiva les consultes d’entrada i generar respostes que estan en línia amb el context.
El model de llenguatge es pre entrena utilitzant grans quantitats de dades textuals d’internet, amb l’objectiu d’aprendre els patrons, les estructures gramaticals i les relacions semàntiques del llenguatge. Aquest pre entrenament permet a ChatGPT adquirir un coneixement ampli sobre una gran varietat de temes i usos del llenguatge humà.
Un aspecte clau de l’arquitectura és la seva capacitat d’adaptació i ajustament. Després del pre entrenament, el model pot ser finament ajustat en tasques específiques o dominis concrets utilitzant dades addicionals. Aquest procés de finetuning permet a ChatGPT produir respostes més precises i adequades.
Components clau
Els components clau de l’arquitectura de ChatGPT són:
- Transformers: Estructura neuronal que permet processar seqüències de text i captar les relacions a llarg termini entre les paraules. Amb múltiples capes es pot processar i generar respostes coherents i contextualment rellevants.
- Mecanismes d’atenció (Self-attention): Son uns mecanismes que permeten que el model prioritzi la informació dins d’una seqüència de paraules, establint connexions i comprenent millor el context.
- Capes de retroalimentació (Feed-forward layers): Aquestes capes són responsables de processar la informació de manera no lineal i realitzar transformacions complexes en les representacions de les paraules. Això permet millorar la generació de llenguatge obtenint respostes més sofisticades.
- Model de llenguatge pre entrenat: Aquest model és entrenat amb una gran quantitat de dades textuals de la web per adquirir un coneixement ampli sobre el llenguatge humà. Aquest pre entrenament proporciona una base sòlida per la generació de respostes en les converses.
- Ajustament i adaptació: L’arquitectura permet adaptar-se a tasques o sectors específics. Després del pre entrenament, el model es pot ajustar utilitzant dades d’entrenament addicionals, permetent una millor adaptació a les necessitats concretes de l’aplicació.
- Capa de descodificació: És la responsable de generar les respostes en converses. Utilitzant les representacions internes del model i les tècniques d’atenció, aquesta capa, converteix la informació en una seqüència de paraules coherents i significatives com a resposta a les consultes d’entrada.
Beneficis
Com a beneficis principals s’ofereixen:
- Generació de respostes coherents i contextualment rellevants: Millora la qualitat de les interaccions entre humans i màquines, proporcionant respostes més naturals i comprensibles.
- Flexibilitat i adaptabilitat: Es permet utilitzar en una àmplia gamma d’aplicacions, com ara: xatbots, assistents virtuals i sistemes de suport al client, adaptant-se a les necessitats particulars de cada context.
- Capacitat de processament de llenguatge avançat: Els mecanismes d’atenció i les capes de retroalimentació permeten captar les relacions entre les paraules i processar la informació de manera no lineal, millorant la comprensió del llenguatge humà.
Diagrames de flux ChatGPT
Aquests diagrames de flux reflecteixen com funciona GPT-4 en un entorn de conversa:
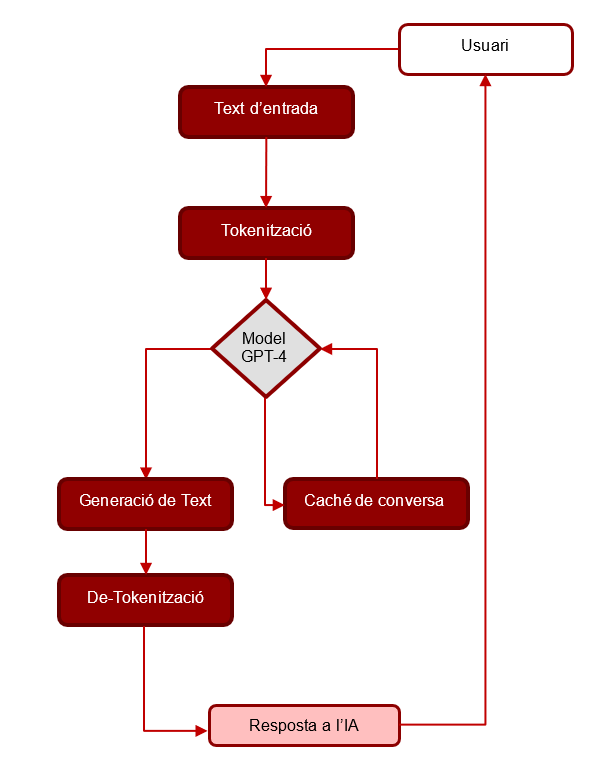
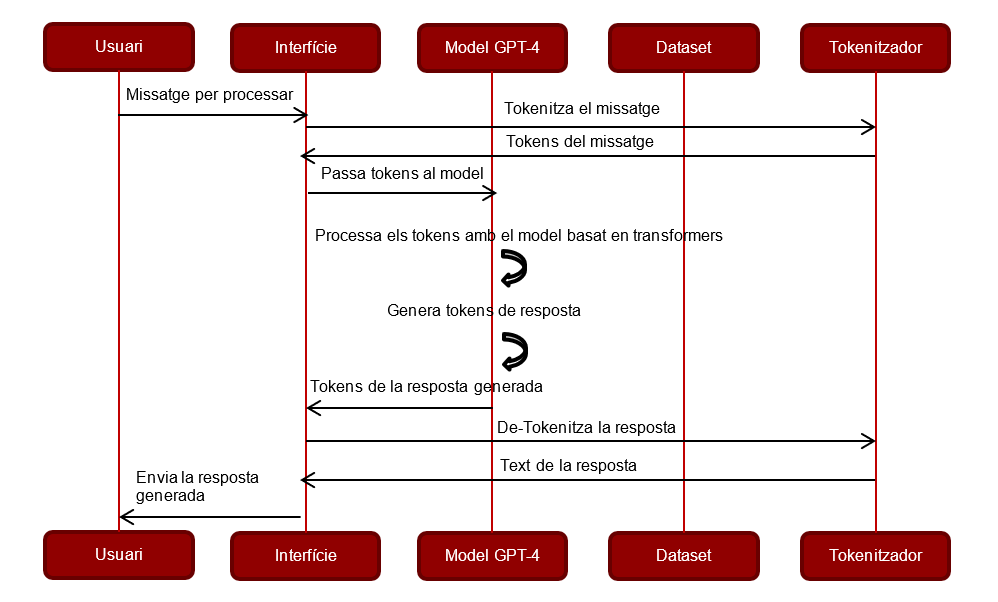
- (1) L’usuari introdueix un text d’entrada.
- (2) El text d’entrada es tokenitza per GPT-4.
- (3) Els tokens van al model GPT-4, on es processen.
- (4) El model GPT-4 preveu els següents tokens basats en la cache de conversa passada i el text d’entrada.
- (5) Es genera el text de recuperació com a resposta.
- (6) El text generat es des-tokenitza per GPT-4.
- (7) La resposta de l’AI (Intel·ligència artificial) es mostra a l’usuari.
- (8) El model GPT-4 actualitza la cache de conversa amb les dades d’aquesta interacció.
Entrenament del model de Llenguatge
Descripció general
L’entrenament del model de llenguatge per ChatGPT és un procés iteratiu que implica la recopilació de dades, el pre processament, l’entrenament, l’avaluació i l’adequació . Aquest procés és crucial per aconseguir un model de llenguatge coherent i capaç de generar respostes adequades en diferents contextos de conversa.
A continuació, es presenta una visió general d’aquest procés:
- Recopilació de dades: La primera etapa implica la recopilació d’una gran quantitat de dades de conversa, que serveixen com a base pel model de llenguatge. Aquestes dades poden provenir de diferents fonts, com ara xats en línia, fòrums de discussió o altres fonts de conversa.
- Pre processament de dades: Un cop recopilades les dades, s’han de pre processar per eliminar informació innecessària i adaptar-les per l’entrenament del model. Això pot implicar tasques com ara la tokenització , la normalització de text i la detecció de frases.
- Entrenament del model: Aquesta etapa, implica la utilització de tècniques d’aprenentatge automàtic, com ara l’entrenament amb supervisió o l’entrenament sense supervisió, perquè el model aprengui a generar respostes coherents i contextualment rellevants.
- Avaluació del model: Després de l’entrenament, és important avaluar el rendiment del model per determinar la seva eficàcia. Això es pot fer mitjançant mètriques com ara la perplexitat o realitzant proves de qualitat, en què es comparen les respostes generades amb respostes humanes.
- Ajustament e iteració: En funció del rendiment del model, es poden realitzar ajustos o millores per aconseguir un millor resultat tot implicant canvis en els hiperparàmetres del model, l’augmentació de dades o altres tècniques d’optimització.
Tècniques utilitzades
L’entrenament de ChatGPT fa servir tècniques com s’ha especificat en un punt anterior de l’article, amb transformers, aprenentatge amb supervisió o sense supervisió, transferència d’aprenentatge i millora de la generació per generar respostes creïbles.
A continuació, s’enumeren algunes de les tècniques més comuns utilitzades en aquest procés:
- Transformers: consisteix en capes d’atenció que permeten captar relacions a llarg abast entre les paraules.
- Aprendre amb supervisió: En l’entrenament inicial de ChatGPT, es pot utilitzar l’aprenentatge amb supervisió, que implica tenir parells d’entrada i sortida de text etiquetats. En aquest cas, el model intenta aprendre a generar la resposta correcta per a cada entrada. Això requereix una gran quantitat de dades etiquetades.
- Aprendre sense supervisió: Un enfocament alternatiu és l’entrenament sense supervisió, en el que el model és exposat a grans quantitats de dades sense cap supervisió específica. En aquest cas, el model intenta capturar patrons i distribucions del llenguatge a partir de les dades d’entrada sense cap informació de sortida específica.
- Transferència d’aprenentatge: És una tècnica que permet utilitzar models pre entrenats en una tasca i reutilitzar-los en altres tasques relacionades.
- Millora de la generació: Per millorar la qualitat de les respostes generades per ChatGPT, es poden utilitzar tècniques com la puntuació de diversitat, que fomenten la generació de respostes més variades i no repetitives. També es poden utilitzar tècniques de descodificació més avançades, com l’enfocament top-k o el nucli ponderat, per millorar la fluïdesa de les respostes generades.
Reptes i limitacions
L’entrenament del model de llenguatge per a ChatGPT presenta diversos reptes i limitacions. A continuació s’enumeren alguns dels principals:
- Manca de dades etiquetades: L’entrenament amb supervisió requereix una gran quantitat de dades etiquetades, és a dir, parells de text d’entrada i sortida. Aconseguir una gran quantitat de dades pot arribar a ser complicat i costós.
- Desigualtat en les respostes: Durant l’entrenament, el model pot mostrar una tendència a donar respostes genèriques o repetitives, ja que pot ser el comportament més comú, provocant la limitació de la diversitat i la creativitat de les respostes generades.
- Manca de contextualització: Els models de llenguatge, com ChatGPT, no disposen d’una memòria persistent per recordar el context a llarg termini. Aquest fet, pot generar dificultats en casos en què es necessiti un coneixement previ o es requereixi recordar informació específica en la conversa.
- Detecció d’informació falsa: Els models de llenguatge poden generar informació falsa o inexacta si no es controlen adequadament. Aquests models no tenen la capacitat de verificar o validar la informació que generen, per la qual cosa, és necessari implementar mecanismes per detectar i mitigar la propagació d’aquest tipus d’informació.
Pre Processament de text
Visió general i tècniques utilitzades per la millora de rendiment
El pre processament de text per ChatGPT implica una sèrie de passos per preparar les dades d’entrada abans de l’entrenament del model. A continuació, s’anomenen algunes de les tècniques utilitzades més significatives:
- Tokenització: És el procés de dividir el text en unitats més petites, anomenades tokens. En aquesta etapa, les frases són dividides en paraules o subparaules per facilitar el processament posterior incloent espais en blanc o aplicant algoritmes de tokenització específics.
- Normalització: Consisteix en estandarditzar el text, de manera que s’eliminen o substitueixen elements no desitjats com caràcters especials, emojis, adreces web o números.
- Eliminació de soroll: Els xats o les converses en línia poden contenir soroll o informació innecessària, com ara salutacions, agraïments o interrupcions. En aquesta etapa, es pot eliminar aquest soroll per deixar només la informació rellevant.
- Eliminació d’entitats personals: És important protegir la privadesa i la seguretat de les persones que han participat en les converses que es fan servir per l’entrenament. Per tant, s’ha de garantir que no es revelin dades personals com ara noms de persones, adreces o números de telèfon.
- Submostratge o filtratge: Les dades de conversa poden ser massa extenses o tenir una gran quantitat de repeticions. Per reduir la complexitat i millorar l’eficiència de l’entrenament, es pot utilitzar submostratge o filtratge per seleccionar només una part de les dades o eliminar seqüències redundants.
- Segmentació de seqüències llargues: Les seqüències llargues poden presentar dificultats en el processament i l’entrenament eficient del model. Per abordar aquesta qüestió, les seqüències es poden dividir en parts més petites per adaptar-se als requisits de llargada del model.
- Eliminació de signes de puntuació i caràcters especials: Els signes de puntuació, els símbols i altres caràcters especials, no aporten molta informació al model de llenguatge. Eliminar-los ajuda a reduir el soroll i simplificar el procés d’entrenament.
- Correcció ortogràfica: Les dades de text sovint contenen errors ortogràfics o errades tipogràfiques. Fer servir tècniques de correcció ortogràfica, com ara utilitzar diccionaris específics del llenguatge o algoritmes com la distància de Levenshtein, pot millorar la qualitat de les dades d’entrada.
Afinament i adaptació
Visió general
L’afinament i l’adaptació són etapes importants per aconseguir un millor rendiment i personalització del model de llenguatge en ChatGPT.
A continuació, es presenta una visió general d’aquestes etapes:
- Afinament (Fine-tuning): Després de l’entrenament inicial del model de llenguatge, es pot procedir amb l’afinament per adaptar-lo a un sector o tasca específica. Aquest procés implica continuar l’entrenament utilitzant dades addicionals i específiques per la tasca desitjada, permetent que el model aprengui i s’adapti millor a les característiques del sector o tasca específica.
- Transferència d’aprenentatge (Transfer Learning): En comptes de començar des de zero, es carrega un model preentrenat amb una gran quantitat de dades de text general. Això permet al model inicialitzar-se amb un coneixement previ i accelerar el procés d’ajustament per a la tasca específica.
- Augmentació de dades (Data Augmentation): És una tècnica que permet augmentar la quantitat de dades d’entrenament mitjançant diverses transformacions i variacions de les dades originals. S’inclouen la substitució de sinònims, la inversió de paraules, l’agregació de soroll o altres modificacions.
- Sintonització d’hiperparàmetres (Hyperparameter Tuning): És un procés iteratiu que requereix ajustar i experimentar amb diferents configuracions per trobar la combinació òptima per la tasca. Permet incloure l’ajust de la mida de lot, la taxa d’aprenentatge, el nombre de capes, els pesos de regularització, entre d’altres.
- Validació i avaluació: Es poden identificar àrees de millora i prendre decisions per a l’afinament posterior al validar el rendiment i identificar possibles problemes o limitacions.
- Afinament del les últimes capes: Una tècnica habitual és congelar els pesos dels primeres capes del model de llenguatge i ajustar només les últimes capes per adaptar-les a la tasca específica, permetent que el model conservi el coneixement general del llenguatge i només aprengui les característiques particulars de la tasca.
Beneficis i limitacions
A continuació s’anomenen alguns dels beneficis de l’afinament i adaptació:
- Millora del rendiment de la tasca: Resultat en respostes més precises, coherents i rellevants pels usuaris.
- Personalització: El model s’adapta millor a les necessitats de l’usuari o de la tasca en qüestió, oferint respostes més ajustades i contextualment rellevants.
- Reducció del requeriment de dades d’entrenament: Redueix la necessitat de tenir grans quantitats de dades d’entrenament per obtenir bons resultats, ja que es pot aprofitar el coneixement preexistent del model.
- Millora de l’eficiència d’entrenament: Es pot ser més eficient en termes de temps i recursos computacionals en comparació amb l’entrenament des de zero.
Però també s’hi poden trobar certes limitacions en l’afinament i adaptació:
- Dependència de les dades d’entrenament: Si les dades són limitades o no representen adequadament la variabilitat de la tasca, l’afinament pot ser menys efectiu.
- Risc de sobre ajustament: Cal vigilar i gestionar el risc de sobre ajustament per evitar que el model esdevingui massa específic i menys adaptable.
- Necessitat de coneixement expert: Es requereixen coneixements experts per triar adequadament els hiperparàmetres, el conjunt de dades d’entrenament i altres factors relacionats.
Mecanismes d’Atenció
Visió general
A ChatGPT, s’utilitzen mecanismes d’atenció per capturar relacions i dependències entre les paraules i generar respostes coherents. A continuació, es presenta una visió general d’aquests mecanismes:
- Self-Attention (Atenció interna): Cada paraula d’entrada té una interacció amb totes les altres paraules, incloent-se a si mateixa, fent que el model tingui una comprensió contextual de cada paraula basant-se en tot el context disponible.
- Multi-Head Attention (Atenció de múltiples capes): S’utilitza l’atenció de múltiples capes per millorar la representació del context permetent al model, capturar diferents relacions i característiques al text.
- Masked Attention (Atenció emmascarada): Serveix per evitar que el model accedeixi a informació futura durant l’entrenament.
- Cross-Attention (Atenció creuada): S’utilitza quan s’integren diferents seqüències d’entrada, com ara el context de la conversa i una pregunta o instrucció. Permet al model centrar-se en una seqüència mentre atén les altres seqüències d’entrada. Això és útil per a tasques de generació de respostes basades en el context.
- Relative Positional Encoding (Codificació posicional relativa): Per capturar la informació de posició relativa entre les paraules, s’aplica una codificació posicional relativa. Aquesta tècnica distingeix les relacions de posició entre paraules properes i llunyanes en una seqüència.
Tipus de mecanismes
El mecanisme d’atenció anomenat “Self-Attention” o “Scaled Dot-Product Attention” és el més utilitzat a l’arquitectura de ChatGPT i proporciona una capacitat clau per capturar relacions entre les paraules d’una seqüència de text. A més de l’atenció interna, també fa servir l’atenció creuada o “Cross-Attention” en certes circumstàncies, especialment quan s’integren múltiples seqüències d’entrada com ara el context de la conversa i una pregunta o instrucció. L’atenció creuada permet que el model generi respostes contextualment rellevants i coherents en relació a aquestes múltiples seqüències d’entrada.
Un altre mecanisme molt utilitzat a ChatGPT és el “Multi-Head Attention”. Aquest amplia la capacitat del model utilitzant atenció simultàniament. Cada una té una projecció lineal diferent, en el que permet capturar diferents tipus de relacions i característiques en el text. El Multi-Head Attention ajuda a millorar la representació del context i a capturar relacions més diverses i complexes entre les paraules.
En resum, aquests mecanismes són clau per capturar relacions, entendre el context i generar respostes coherents i contextualment rellevants.
Tècniques d’Optimització
Visió general
Les tècniques d’optimització són crucials per millorar el rendiment i l’eficiència. A continuació, es presenta una visió general de les més comunes utilitzades en aquest context:
- Optimització basada en gradient (Gradient-based optimization): Es basa en l’ús del gradient de la funció d’error per ajustar els pesos del model. Els algoritmes d’optimització com l’algorisme d’optimització estocàstica del gradient o l’algoritme d’optimització adaptativa momentània (Adam) són exemples comuns d’algoritmes basats en gradient.
- Regularització (Regularization): És una tècnica utilitzada per prevenir el sobre ajustament i millorar la generalització del model s’aconsegueix afegint termes de regularització als pesos del model, com ara la regularització L1 o L2. La regularització ajuda a controlar la complexitat del model i evitar que s’ajusti massa a les dades d’entrenament específiques.
- Descomposició de l’espai latent (Latent Space Decomposition): Aquesta tècnica implica descompondre l’espai latent del model en subespais més petits i més manejables reduint la complexitat i facilitant l’entrenament del model. Un exemple és la descomposició de les capes d’atenció en subcapes per millorar l’eficiència del càlcul i reduir la càrrega computacional.
- Ajustament de taxa d’aprenentatge (Learning Rate Scheduling): És una tècnica que modifica dinàmicament la taxa d’aprenentatge durant l’entrenament. Permet adaptar la velocitat d’aprenentatge del model en funció de l’evolució del procés d’entrenament. Els esquemes d’ajustament de la taxa d’aprenentatge poden ser basats en el pas de temps, en funció de l’error o segons altres criteris.
- Optimització distribuïda (Distributed Optimization): És una tècnica que permet accelerar l’entrenament de models de llenguatge utilitzant múltiples nodes o dispositius de càlcul. Reparteix la càrrega computacional i processa les dades d’entrenament de forma paral·lela, millorant així l’eficiència i el temps d’entrenament.
En resum, totes aquestes tècniques són essencials per millorar el rendiment, l’eficiència i la generalització de ChatGPT. Aquestes s’apliquen per aconseguir resultats òptims i obtenir un model de llenguatge més eficaç i precís.
Limitacions
Les tècniques d’optimització utilitzades enfronten diversos desafiaments i tenen algunes limitacions que és important tenir en compte. A continuació, es presenten algunes d’aquests desafiaments i limitacions:
- Complexitat computacional: Les tècniques d’optimització avançades, com l’ajustament de hiperparàmetres o l’optimització basada en gradient, poden ser computacionalment exigents i requerir d’una gran quantitat de recursos computacionals. L’entrenament de models de llenguatge com ChatGPT pot ser intensiu en termes de temps i requerir infraestructura potent per executar les tasques de manera eficient.
- Requeriments de dades d’entrenament: Algunes tècniques, com ara la transferència d’aprenentatge, requereixen d’una gran quantitat de dades d’entrenament rellevants i de qualitat. Si aquestes dades són limitades o no representen adequadament la tasca o el domini específic, l’optimització pot ser menys efectiva.
- Sobreafinament: Aquestes tècniques poden ser susceptibles de generar models que s’ajustin massa a les dades d’entrenament i tinguin dificultats per generalitzar noves dades o situacions. Cal tenir cura de no sobreajustar el model a les dades d’entrenament específiques i utilitzar tècniques de regularització per millorar la seva capacitat de generalització.
- Limitacions del conjunt de dades: Si el conjunt de dades és petit, poc divers o no representa adequadament la varietat de situacions o dominis que el model enfrontarà, l’optimització pot ser menys efectiva.
- Interdependència de les tècniques: Els canvis en una tècnica poden requerir ajustaments en altres tècniques o afectar el rendiment global del model. Cal considerar aquestes interdependències i ajustar adequadament les tècniques utilitzades.
Implementació i Escalabilitat
La implementació i l’escalabilitat són factors clau en l’ús del ChatGPT. La implementació adequada implica la configuració del model d’una interfície d’usuari eficient, mentre que l’escalabilitat implica considerar el paral·lelisme, la càrrega equilibrada, l’optimització de la infraestructura i la gestió de la memòria per un rendiment òptim en escenaris d’ús intensiu.
A continuació, es presenta una visió general d’aquests aspectes.
Implementació
Implica la configuració del model i el desplegament d’un sistema que permeti interactuar amb l’usuari de manera eficient. Alguns punts clau inclouen:
- Gestió de la infraestructura: Es requereix d’una infraestructura adequada per l’execució de ChatGPT com l’ús de servidors o recursos computacionals al núvol per l’entrenament i la inferència del model.
- Preparació de dades: És necessari realitzar el pre processament de les dades d’entrenament i preparar-les per l’entrenament. S’ha d’incloure la neteja de les dades, la segmentació en seqüències adequades i la generació de conjunts de dades d’entrenament i prova.
- Selecció de l’arquitectura del model: Cal triar els components clau, com ara les capes d’atenció, la dimensió latent i altres hiperparàmetres importants.
- Implementació del sistema d’interfície d’usuari: Cal desenvolupar una interfície d’usuari amigable i eficient per la interacció amb els usuaris. I pot ser a través d’aplicacions web, aplicacions de xat o altres formes d’interfície d’usuari.
Escalabilitat
És un factor clau per gestionar l’ús de ChatGPT en escenaris amb un gran volum de trànsit d’usuaris o en aplicacions de xat a gran escala. A continuació, s’esmenen algunes consideracions a tenir en compte:
- Paral·lelisme: Millorar la velocitat i l’escalabilitat aprofitant el paral·lelisme permet que múltiples dispositius o servidors, puguin processar diverses interaccions simultàniament.
- Càrrega equilibrada: A mesura que el trànsit d’usuari augmenta, és important garantir una càrrega equilibrada per evitar punts febles en el sistema. Aquest fet implica l’ús de tècniques com la distribució de càrrega i la distribució de les interaccions d’usuari a través de diferents nodes o servidors.
- Optimització de la infraestructura: Es pot optimitzar la infraestructura mitjançant l’escalabilitat automàtica, l’ús eficient dels recursos computacionals i l’optimització de la gestió de memòria.
- Gestió de la memòria: L’escalabilitat pot requerir la gestió eficient de la memòria en entorns amb un gran volum de dades i interaccions d’usuari com l’ús de memòria cau, l’ús de memòria compartida o altres estratègies per optimitzar l’ús de la memòria del sistema.
Taula comparativa ChatGPT 3.5 vs ChatGPT 4.0
En aquesta taula es mostren les característiques tècniques generals que permeten diferenciar les darreres versions disponibles de ChatGPT.
| Característica | ChatGPT-3.5 | ChatGPT-4 |
|---|---|---|
| Arquitectura del model | GPT-3 | GPT-4 |
| Dades d’entrenament | Pre entrenat amb text divers d’internet | Pre entrenat amb text divers d’ internet |
| Límit de coneixement | Setembre de 2021 | N/A (Suposant que ChatGPT-4, està entrenat després de setembre de 2021) |
| Intel·ligència conversacional | Sí | Sí |
| Comprensió contextual | Sí | Sí |
| Coherència de resposta | A vegades pot generar respostes incoherents o sense sentit | Millora en la coherència i la rellevància de les respostes |
| Límit de paraules | Fins a 2048 tokens | Millora probablement, però no es coneix un límit específic |
| Suport multimodal | No | Millora probablement, però no es coneixen les capacitats específiques |
| Rendiment | Temps de resposta més lent en comparació amb GPT-4 | Millora probablement, però no es coneixen les mètriques de rendiment específiques |
| Precisió | Alta precisió en la comprensió i generació de text | Millora probablement, però no es coneixen les mètriques de precisió específiques |
| Afinament detallat | Disponible per a personalització i tasques específiques de domini | Probablement disponible, però no es coneixen els detalls específics |
| Mitigació de prejudicis | Mesures de mitigació de prejudicis limitades | Millora probablement, però no es coneixen les mesures específiques |
Consideracions ètiques
Les consideracions ètiques en l’arquitectura de ChatGPT inclouen la responsabilitat, la prevenció de biaixos i discriminació, la privadesa i seguretat de les dades, la transparència, la supervisió i control, així com el consentiment i la participació dels usuaris. És essencial abordar aquestes consideracions per garantir que sigui utilitzat de manera ètica i responsable.
Les consideracions ètiques són un aspecte crític en el disseny i l’ús de l’arquitectura.
A continuació, es presenta una visió general d’algunes d’aquestes consideracions a tenir en compte:
- Responsabilitat: És essencial assumir la responsabilitat de les conseqüències de l’ús de ChatGPT. Cal garantir que el sistema sigui utilitzat de manera ètica i no generi danys o perjudicis als usuaris o a altres parts interessades.
- Biaix i discriminació: L’arquitectura de ChatGPT pot aprendre i reflectir els biaixos presents en les dades d’entrenament. És important identificar i abordar els biaixos per garantir que el sistema no discrimini ni perpetuï estereotips o desigualtats.
- Privadesa i seguretat: És fonamental garantir la privadesa i la seguretat de les dades dels usuaris. Cal implementar mesures adequades per protegir la informació personal i evitar el mal ús o l’accés no autoritzat a les dades.
- Transparència: És important ser transparent sobre com funciona l’arquitectura i proporcionar les explicacions clares sobre com s’obtenen les respostes generades fent que els usuaris comprenguin millor el sistema i puguin prendre decisions.
- Supervisió i control: Cal establir mecanismes de supervisió i control per evitar l’ús indegut o maliciós de ChatGPT. Cal aplicar polítiques d’ús, implementació de sistemes de moderació o altres formes de control per garantir un ús responsable.
- Consentiment i participació: És important obtenir el consentiment dels usuaris per utilitzar les seves dades i assegurar-se que són conscients de com s’utilitzen.
El futur de ChatGPT i el seu impacte potencial en la Indústria
El futur de ChatGPT té un impacte potencial significatiu en la indústria del processament del llenguatge natural. Amb millores contínues en el rendiment, aprenentatge multimodal, personalització, adaptabilitat, suport per a tasques especialitzades, col·laboració entre humans i màquines, i ús en tasques creatives, ChatGPT pot transformar la forma en què s’interactuï amb les màquines i s’utilitzi el llenguatge natural en diferents àmbits de la vida quotidiana i empresarial.
El futur de ChatGPT és prometedor i té el potencial de revolucionar significativament la indústria de processament de llenguatge natural (NLP).
A continuació, es detallen algunes tendències i impactes potencials del seu futur en aquesta industria:
- Millora contínua del rendiment: Es preveu que els models de llenguatge continuïn millorant en termes de generació de llenguatge natural. A mesura que es desenvolupin nous algoritmes, tècniques de formació i models més grans, es podria aconseguir un rendiment encara millor, amb respostes més precises, coherents i contextualment rellevants.
- Aprenentatge multimodal: Els futurs desenvolupaments podrien permetre que s’expandeixi per la comprensió i generació multimodal, no només en text, sinó també en imatges, àudio i altres formats de dades. Aquest fet obriria noves oportunitats per la interacció amb l’usuari i l’aplicació en tasques de processament de llenguatge que combinen múltiples modalitats.
- Personalització i adaptabilitat: Es podria millorar la capacitat per adaptar-se millor als usuaris individuals i als contextos específics. Això podria incloure una millor comprensió dels estils de conversa, preferències de l’usuari i adaptació a diferents sectors o indústries.
- Suport per tasques especialitzades: Es preveu que ChatGPT continuï sent adaptat per tasques especialitzades de NLP. Inclou aplicacions en sectors com la salut, el comerç electrònic, el servei al client, l’educació i altres àmbits on la generació de llenguatge natural és crucial fet que milloraria l’eficiència i l’eficàcia de les tasques relacionades amb el llenguatge en aquests sectors.
- Col·laboració entre humans i màquines: El futur també implica una millor col·laboració entre humans i màquines. Els sistemes de xat basats en ChatGPT podrien ser utilitzats com assistents intel·ligents pels usuaris per millorar la productivitat, la comunicació i l’assistència en diferents àmbits.
- Ús en tasques creatives i artístiques: El futur pot incloure l’aplicació en tasques creatives i artístiques, com ara generació de textos literaris, creació de diàlegs per la indústria del cinema i la televisió, i altres aplicacions en les quals el llenguatge és fonamental per la creació artística.
Referències
Glossari
- NPL/PLN: processament del llenguatge natural.
- GPT: transformador generatiu pre-entrenat.
- Transformers: xarxes neurals capaces de processar fluxos de dades enormes mitjançant un mecanisme d’atenció, per proporcionar respostes útils en tasques de processament del llenguatge natural.
- Tokenització: és el procés de descompondre un document de text en fitxes individuals, que després es poden utilitzar com a entrades per l’aprenentatge automàtic.
- Hiperparametres: variables externes que s’estableixen abans que comenci el procés d’entrenament i que no es poden aprendre de les dades d’entrenament.
###### **Àrea d'Arquitectura d'Entorn Digital de Treball i Comunicacions**
###### **Direcció Infraestructures**
comments powered by Disqus